AI Data Storage
RAG сейчас находится в бета-версии. Цены, поведение и ограничения могут измениться.
Назначение
AI Data Storage (RAG) — это компонент платформы Nodul, предназначенный для хранения и индексации текстовых файлов, изображений и других источников знаний.
Этот инструмент предназначен в первую очередь для использования совместно с ИИ-агентом — он предоставляет документы в виде чанков, которые агент затем может использовать для генерации ответов.
Варианты использования:
- Загрузка и хранение структурированного или неструктурированного контента
- Генерация векторных эмбеддингов для быстрого семантического поиска
- Выполнение поисковых запросов на естественном языке
- Подключение к узлу RAG Search внутри сценария
Как получить доступ
Вы можете получить доступ к этой функции через Data Storage → AI Data Storage (RAG) в левом меню.
Создание хранилища
Нажмите Create Storage, чтобы открыть окно настройки:
Заполните обязательные поля: Storage Name, Chunk Size, Chunk Overlap
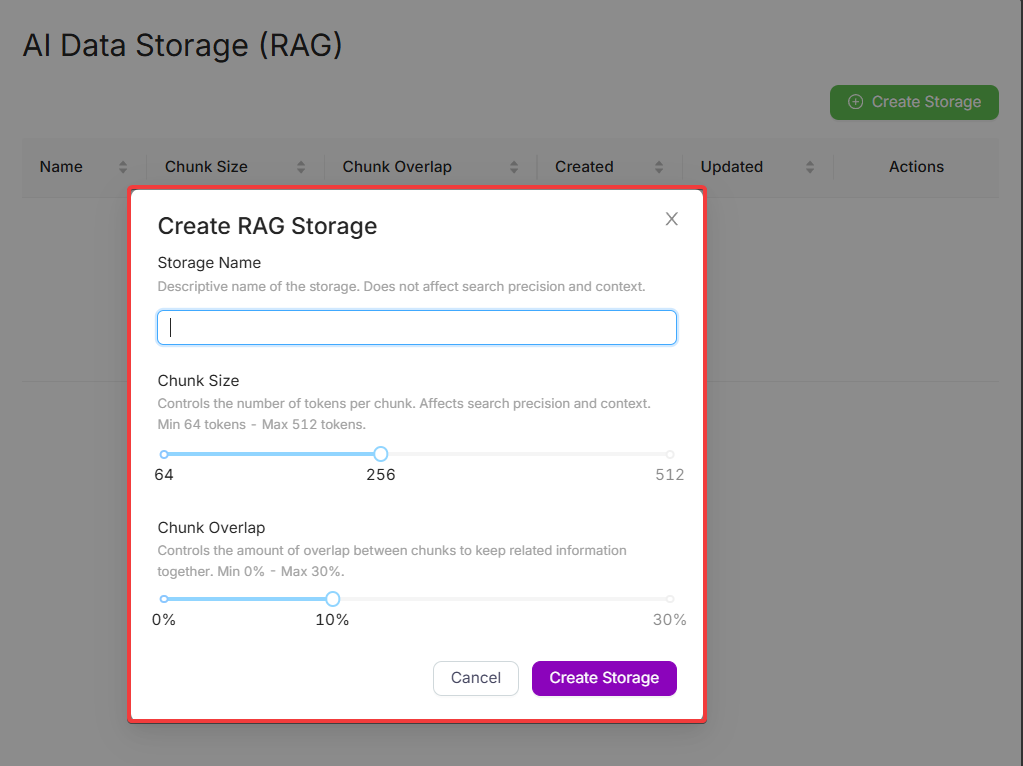
Что такое Chunk Size и Overlap?
- Chunk Size — количество токенов в одном чанке. Меньшие чанки обеспечивают более высокую точность, но увеличивают общее количество чанков.
- Chunk Overlap — процент перекрытия токенов между соседними чанками. Помогает сохранять контекст между ними.
Управление хранилищем
Созданные хранилища отображаются в таблице:
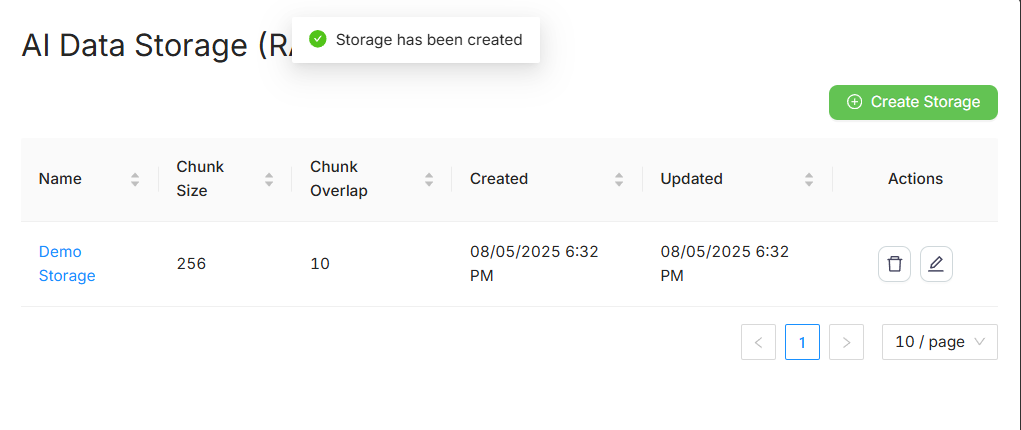
| Поле | Описание |
|---|---|
| Name | Название хранилища |
| Chunk Size | Количество токенов на чанк |
| Chunk Overlap | Перекрытие между чанками в % |
| Created | Дата создания |
| Updated | Дата последнего обновления |
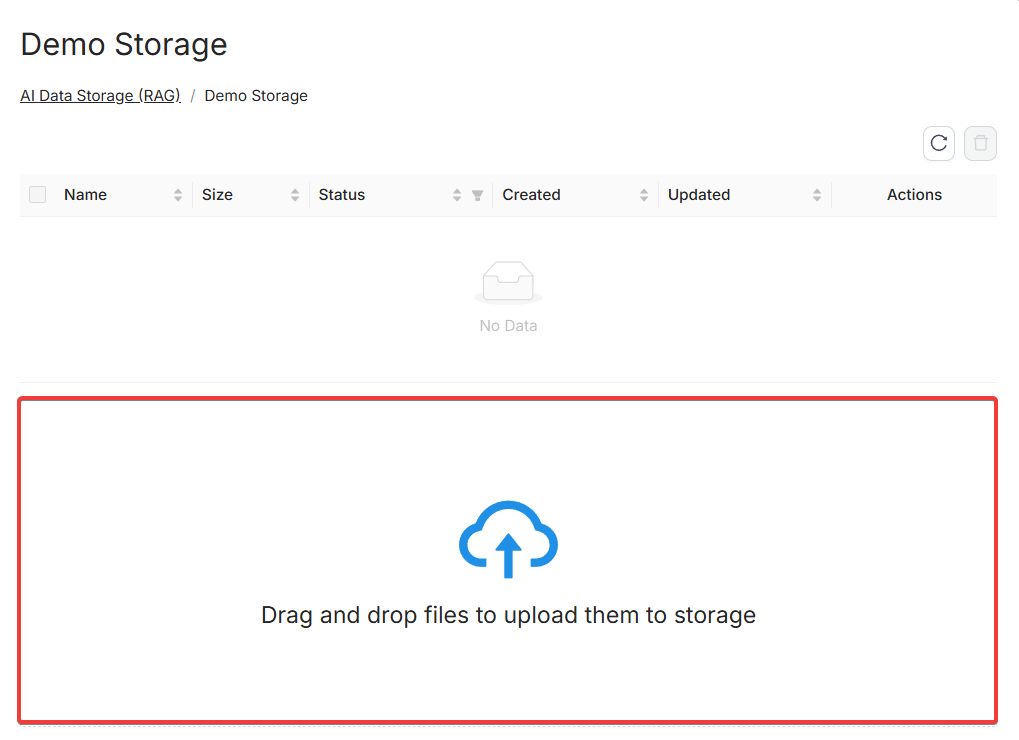
Загрузка файлов
Откройте хранилище для доступа к интерфейсу загрузки. Поддерживается перетаскивание файлов.
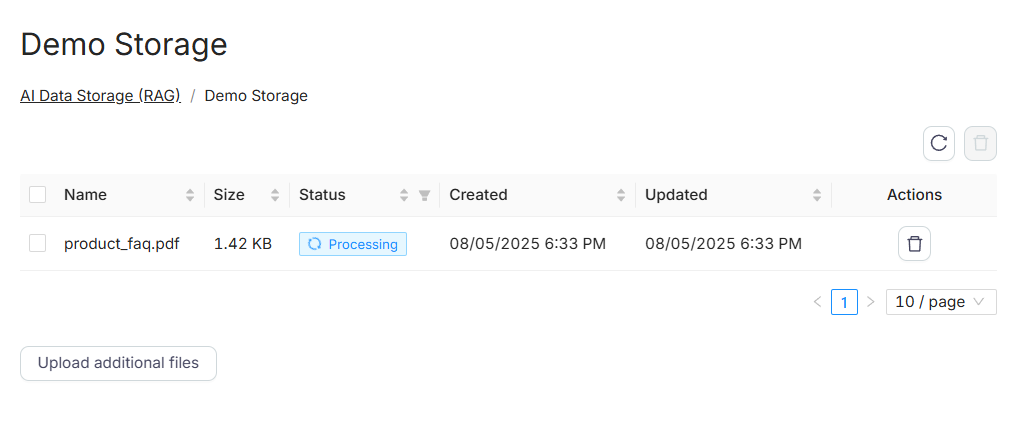
После загрузки:
- Каждый файл обрабатывается и индексируется (статус: Processing)
- Файлы отображаются с размером, датой загрузки и статусом
- Редактирование или скачивание файлов в настоящее время не поддерживается
Мультимодальные функции RAG
Для работы с изображениями и нетекстовыми данными RAG Storage использует продвинутый подход:
- Автоматическое описание изображений: При загрузке изображений (JPEG, PNG) система автоматически генерирует их текстовое описание (краткое содержание) с помощью мультимодальной LLM и индексирует это описание вместе с текстовым контентом.
- Индексация текста: Текст, извлечённый через OCR из изображений (или PDF-файлов), также разбивается на чанки и индексируется.
Это позволяет ИИ-агенту эффективно находить ответы на вопросы на основе как текстового, так и визуального контента.
Функции и ограничения
| Функция | Статус |
|---|---|
| OCR | Поддерживается (английский и русский) |
| Загрузка изображений | Поддерживается (если изображение содержит текст) |
| Редактирование файлов | Не поддерживается |
| Скачивание файлов | Пока недоступно |
| Автоматическая индексация | Да |
| Поддерживаемые форматы | PDF, TXT, JSON, MD, PNG, JPG и другие |
| Загрузка через сценарий | Пока не поддерживается |
Технические детали
| Параметр | Значение |
|---|---|
| Максимальный размер файла | 20 МБ (планируется 50 МБ) |
| Лимит векторов | 5 000 000 векторов на аккаунт |
| Тарификация | 0.0066 PNP токенов за страницу, списание только при загрузке файла |
Тарификация
- PNP токены списываются при загрузке файла
- Тарификация основана на страницах/чанках
- Стоимость векторизации: 0.0066 PNP токенов за страницу
- "1 страница" соответствует примерно 1000 словам или 5000 символам текста
- Для неструктурированных данных (например, TXT, MD) применяется та же линейная модель тарификации — стоимость пропорциональна общей длине текста
Примеры:
-
10 страниц (PDF/DOCX/PPTX) → 0.066 PNP токенов ($0.066)
-
TXT ≈ 10 000 слов (≈ 50 000 символов) → 0.066 PNP токенов ($0.066)
-
MD ≈ 20 000 слов (≈ 100 000 символов) → 0.132 PNP токенов ($0.132)
-
100 страниц → 0.66 PNP токенов ($0.66)
-
Запросы через RAG Search дополнительно не тарифицируются
Использование баз данных из JS-кода
Доступ и взаимодействие с базой данных с помощью JavaScript.
Узел RAG Search
Поиск документов с помощью векторного сходства по запросам на естественном языке в сценариях.
Нужна помощь? Спросите сообщество
Если на странице не хватает деталей или что-то непонятно, напишите на форуме сообщества Nodul: команда и другие пользователи обычно отвечают быстро.
Программное обеспечение распространяется в виде интернет-сервиса, специальные действия по его установке на стороне пользователя не требуются.